The network that never needs any maintenance, along with the associated downtime, hasn’t been built yet. You can plan your own downtime such that impact on your business is minimized, but you are also affected by the maintenance performed by your upstream providers. Usually, such maintenance happens during well-defined maintenance hours and planned outages are communicated well in advance, but it also happens all too often that communication fails and maintenance outages happen unexpectedly. With multiple upstream providers, it can sometimes seem that maintenance downtimes never end!
The network that never needs any maintenance, along with the associated downtime, hasn’t been built yet. You can plan your own downtime such that impact on your business is minimized, but you are also affected by the maintenance performed by your upstream providers. Usually, such maintenance happens during well-defined maintenance hours and planned outages are communicated well in advance, but it also happens all too often that communication fails and maintenance outages happen unexpectedly. With multiple upstream providers, it can sometimes seem that maintenance downtimes never end!
The unfortunate result of downtime on one link is more traffic over the remaining links, which stresses your network and may cause congestion on the remaining links. This is particularly painful when traffic is rerouted over your most expensive provider, or the extra traffic exceeds a commitment and incurs overage charges.
Wouldn’t it be nice if, during downtime on equipment connecting one provider, your network could push traffic (and the associated penalties for broken commits) towards the least expensive provider or providers? While at the same time maintaining stability in your network so non-critical components don’t ‘panic’ and introduce hard to predict destabilization of the already stressed network?
This case study highlights two benefits of using IRP during provider downtime as observed on one of our customers in a live production environment:
- IRP reacts to routine changes as well as outages and other stressful situations without destabilizing the network.
- IRP dynamically adjusts the network both during planned and unplanned downtime and avoids expensive over-commits.
These features were included in IRP by design, and customer data shows that they work as intended.
Our customer has three transit providers. Let’s call them Maintenance, Expensive and Wholesale. Maintenance is the provider that is carrying out maintenance, while Expensive is a relatively expensive provider and Wholesale a relatively cheap one. Note that there were additional transit and peering links that have been left out for the sake of clarity.
The Maintenance provider needed to carry out maintenance on the equipment connected to our customer by disconnecting that equipment for a few minutes on two occasions during the maintenance window, when traffic was low. The first disconnect happened at 0:15 and the second at 0:38. The graphs show the traffic volume for the one-hour interval that includes these downtime events. The vertical axis is in Mbps and uses the same scale for all providers to allow visual comparison between providers. The first graph is for the Maintenance provider:
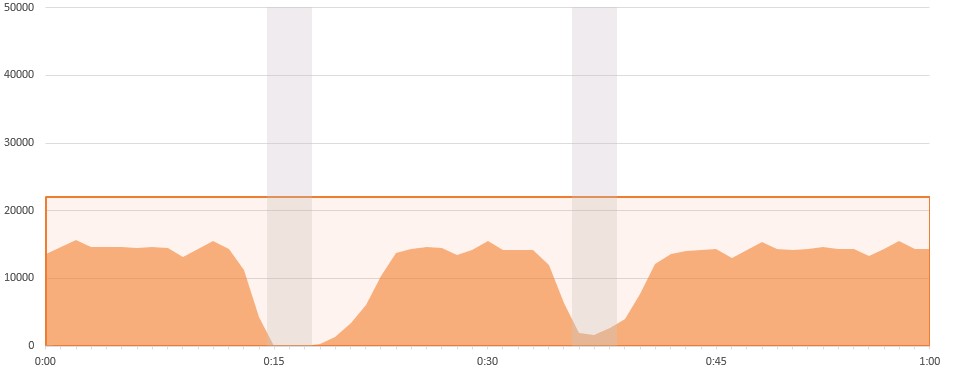
The graph shows network bandwidth usage for the Maintenance upstream provider. Maintenance is carrying approximately 15 – 16 Gbps with a commit level at 22 Gbps. I.e., the customer has paid for 22 Gbps, whether they use it or not. But if they go over 22 Gbps, they have to pay extra. The gray areas highlight the downtime events.
During the downtime of the Maintenance provider, “orphaned” traffic is rerouted over the other providers. The network continues to operate in this stressful situation. Forcing all the orphaned traffic towards only one ISP is suboptimal–it is possible that its coverage area or QoS for some destinations is significantly worse and also the over-commit rates on that provider may be higher. The first step is to trust the BGP information our routers learn from the remaining providers, and route traffic along the most optimal path as usual.
Note that provider Expensive charges significantly more for traffic in excess of the committed level than provider Wholesale. Therefore, as a second step, it’s preferable that orphaned traffic is rerouted such that the agreed commit levels towards both alternative providers are used fully. If there is then any excess traffic, it should go towards the Wholesale provider.
After Maintenance provider is shut down, as expected a lot of traffic is routed through the Expensive provider as shown in the next chart. Bandwidth usage eventually exceeds established commit levels and at that point IRP starts rerouting flows away from the Expensive provider.
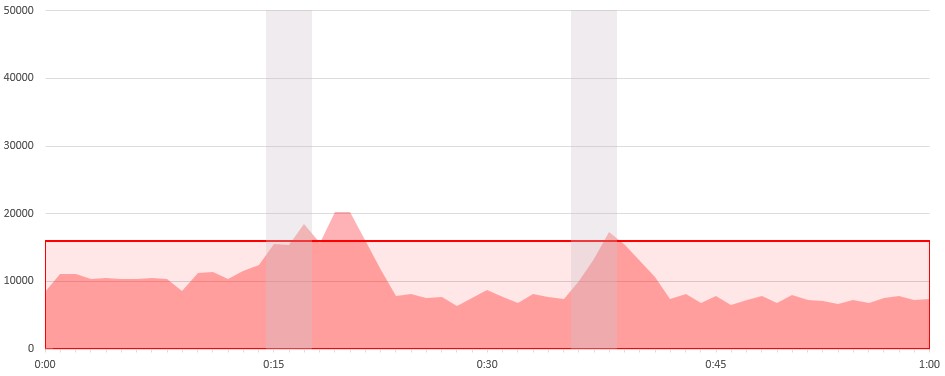
The graph above shows bandwidth usage by the Expensive provider. During the downtime periods on Maintenance (grayed out areas), it handles a lot of additional traffic. Eventually, when the traffic exceeds the configured commit levels (at 16Gbps) IRP starts re-routing traffic. Due to the fact that IRP receives the traffic volume information with a delay of one minute, it takes some time for the IRP’s traffic routing improvements to take effect. As such, traffic exceeds the 16 Gbps commitment for several minutes. IRP’s Commit Control feature only tries to reduce prolonged overloads.
Below is the bandwidth usage during the same period for the Wholesale provider to draw a complete picture. This provider shows significant available capacity—the commitment level is in excess of the 50 Gbps level where the graph tops out—and it has very small penalties for exceeded commits.
To highlight how IRP handles the situation we provide its Improvement counts during the time period in question. The graph shows Improvements that move traffic away from Expensive provider towards other providers. There were no Commit Control Improvements towards the Expensive provider during this time period.
The graph shows the number of Commit Control improvements above the zero line and the number of Performance improvements for each 30-second interval below the zero line.
It is clear that when bandwidth usage on the Expensive provider reaches configured limits, IRP starts pushing traffic away from it. It first only uses Improvements towards the Wholesale provider to reroute traffic over that provider. Later, when the Maintenance provider comes back online and then carries only a very small amount of traffic, Improvements are directed at Maintenance, which thus gets more traffic. If the downtime window had been longer the same pattern of Improvements targeting the Maintenance provider would have shown over a longer period. And eventually IRP reverted back to normal operation.
Please note that the periods where traffic volume exceeded commitments were short enough that no overage charges were incurred as per the usual 95th percentile traffic metering. The graph below shows bandwidth use through each provider during two days with the downtime events clearly visible in the middle of the graph.
The dashed blue line highlights the commit level for the Expensive provider. The dotted blue line shows what was the actual 95th for the day and it is below configured target.
We can conclude that IRP reacts sufficiently fast to prevent any excessive and prolonged overuse on links with fixed commitments. As downtime for maintenance was very short, network behavior reverted back to normal after only a very few and small overuses. In the long term, our customer’s network was able to handle the stress based on some reserve to anticipate a more prolonged downtime window or other potential overload events in the future.